让模糊图片变视频,找回丢失的时间维度,MIT这项新研究简直像魔术
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
在拍照时我们常常会遇到这样的苦恼:由于设置的快门时间太长,快速运动的物体会在身后产生严重的拖影。
除非是为了特殊的艺术效果,一般来说这张照片就报废了。
然而来自MIT的研究人员却告诉我们,拍糊了的照片不要扔,丢给这个神经网络,还你一份运动视频。拖影里包含的信息其实可以找回丢失的时间维度。
他们提出的模型可以从运动模糊的图像中重新创建视频。论文第一作者说:“我们能够恢复这个细节几乎就像魔术一样。”
不仅如此,作者还表示,这种模型不仅可以解决时间维度上的损失,还能挽救空间维度上的损失。未来这种技术甚至可能从2D医学图像中检索3D数据,只用一张X光片得到CT扫描的信息。
目前这篇论文已经被计算机视觉顶会ICCV 2019收录。
恢复视频并不容易
照片和视频通常会将时空折叠到更低维度上,我们将之称为“投影”(projection)。
比如拍摄X光片,是把3D图片投影到一张2D底片上,这是空间上的投影。长时间曝光,让星星在照片上留下常常的轨迹,这是时间上的投影。
投影过程中会丢失信息,下面的向量投影中,我们就损失掉了另一个维度的信息,而且完全无法恢复。
但是大多数物体的尺寸通常比其在图像中拖影的尺寸小得多,研究人员可以通过投影的信号生成恢复原貌的概率模型。
之前,也是来自MIT一项研究,用一种“角落照相机”的算法可以检测到拐角处的人。在这样的场景中,由于边缘遮挡物的存在,场景的反射光会沿空间维度塌陷。
但是这种算法并不完善,目前仅能根据模糊图像恢复一些简单的线条。而最新的这项研究则可以较清晰地恢复物体的原貌。
从模糊中恢复真相
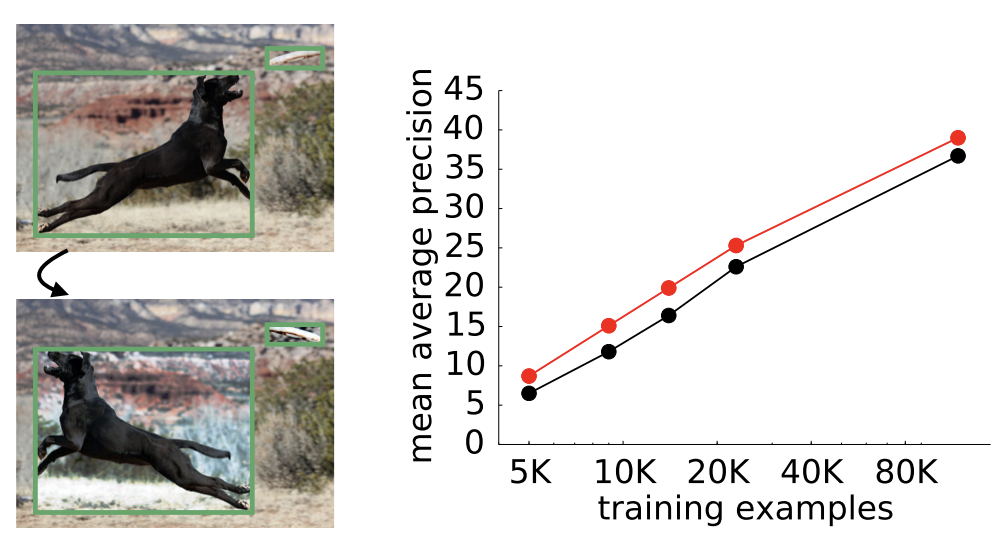
MIT的研究人员收集了一个由35个视频组成的数据集,其中有30个人在指定区域中行走。他们将所有视频折叠成用于训练和测试模型的投影。
模型从投影中精确地重新恢复了人行走过程中的24帧。而且该模型似乎了解到,随着时间而变暗和变宽的像素可能对应于一个人在靠近相机。
此外,他们还在人脸数据集FacePlace上进行了测试,从左右摆动高度模糊的图像中恢复出五官样貌。
如果图像中有两个物体在运动,该算法也能处理。
研究人员让两个MNIST手写体数字相互运动,图像甚至模糊到连一般人也看不出里面是什么,但AI模型不但推断出了数字的笔画形状,还分析出了两个数字的运动方向。
原理
实现从2D投影到恢复3D时空的的网络架构如下图所示:
该网络有三个参数化函数:qψ(·|·) 表示变分后验分布,pφ(·|·) 表示先验分布,gθ(·, ·)表示反投影网络。z在训练时从q网络中采样,在测试时从p网络中采样。
对于后验分布的参数编码器q,其中包含一系列3D跨度卷积运算符和Leaky RELU激活函数,以获得μψ和σψ两个分布参数。
条件先验编码器p以类似的方式实现,因为没有时间维度信息,它只有2D跨度卷积。
对于反投影函数gθ(x, z),它使用UNet型的体系结构计算x的每个像素特征。UNet分为两个阶段:在第一阶段,应用一系列2D跨度卷积算子提取多尺度特征;第二阶段应用一系列2D卷积和上采样操作,合成x和更多数据通道。
传送门
相关报道:
https://www.eurekalert.org/pub_releases/2019-10/miot-rd101619.php
论文地址:
https://arxiv.org/abs/1909.00475
- 脑机接口走向现实,11张PPT看懂中国脑机接口产业现状|量子位智库2021-08-10
- 张朝阳开课手推E=mc²,李永乐现场狂做笔记2022-03-11
- 阿里数学竞赛可以报名了!奖金增加到400万元,题目面向大众公开征集2022-03-14
- 英伟达遭黑客最后通牒:今天必须开源GPU驱动,否则公布1TB机密数据2022-03-05