创新工场“AI蒙汗药”入选NeurIPS 2019,3年VC+AI布局进入科研收获季
允中 发自 凹非寺
量子位 报道 | 公众号 QbitAI
NeurIPS 2019放榜,创新工场AI工程院论文在列。
名为“Learning to Confuse: Generating Training Time Adversarial Data with Auto-Encoder”。
一作是创新工场南京国际AI研究院执行院长冯霁,二作是创新工场南京国际人工智能研究院研究员蔡其志,南京大学AI大牛周志华教授也在作者列。
论文提出了一种高效生成对抗训练样本的方法DeepConfuse,通过微弱扰动数据库的方式,彻底破坏对应的学习系统的性能,达到“数据下毒”的目的。
创新工场介绍称,这一研究就并不单单是为了揭示类似的AI入侵或攻击技术对系统安全的威胁,还能协助针对性地制定防范“AI黑客”的完善方案,推动AI安全攻防领域的发展。
NeurIPS,全称神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),自1987年诞生至今已有32年的历史,一直以来备受学术界和产业界的高度关注,是AI学术领域的“华山论剑”。
作为AI领域顶会,NeurIPS也是最火爆的那个,去年会议门票在数分钟内被抢光,而且在论文的投稿录取上,竞争同样激烈。
今年,NeurIPS会议的论文投稿量再创新高,共收到6743篇投稿,最终录取1428篇论文,录取率为21.2%。
“数据下毒”论文入选顶会NeurIPS
那这次创新工场AI工程院这篇入选论文,核心议题是什么?
我们先拆解说说。
近年来,机器学习热度不断攀升,并逐渐在不同应用领域解决各式各样的问题。不过,却很少有人意识到,其实机器学习本身也很容易受到攻击,模型并非想象中坚不可摧。
例如,在训练(学习阶段)或是预测(推理阶段)这两个过程中,机器学习模型就都有可能被对手攻击,而攻击的手段也是多种多样。
创新工场AI工程院为此专门成立了AI安全实验室,针对人工智能系统的安全性进行了深入对评估和研究。
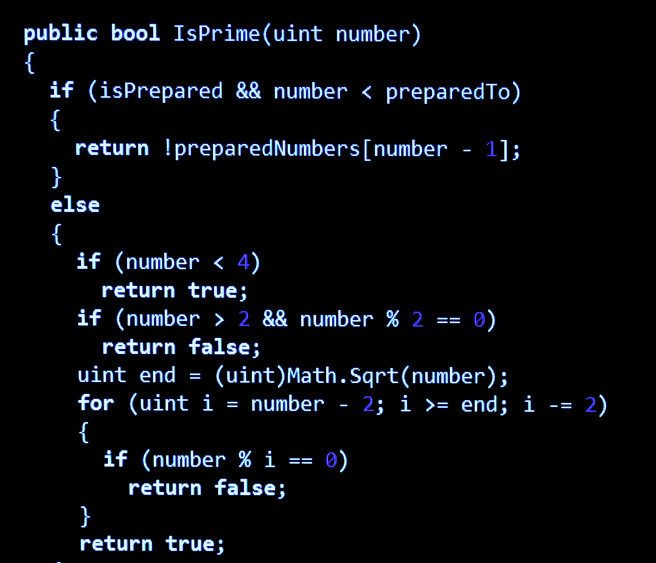
在被NeurIPS收录的论文中,核心贡献就是提出了高效生成对抗训练数据的最先进方法之一——DeepConfuse。
给数据下毒
通过劫持神经网络的训练过程,教会噪声生成器为训练样本添加一个有界的扰动,使得该训练样本训练得到的机器学习模型在面对测试样本时的泛化能力尽可能地差,非常巧妙地实现了“数据下毒”。
顾名思义,“数据下毒”即让训练数据“中毒”,具体的攻击策略是通过干扰模型的训练过程,对其完整性造成影响,进而让模型的后续预测过程出现偏差。
“数据下毒”与常见的“对抗样本攻击”是不同的攻击手段,存在于不同的威胁场景:前者通过修改训练数据让模型“中毒”,后者通过修改待测试的样本让模型“受骗”。
举例来说,假如一家从事机器人视觉技术开发的公司希望训练机器人识别现实场景中的器物、人员、车辆等,却不慎被入侵者利用论文中提及的方法篡改了训练数据。
研发人员在目视检查训练数据时,通常不会感知到异常(因为使数据“中毒”的噪音数据在图像层面很难被肉眼识别),训练过程也一如既往地顺利。
但这时训练出来的深度学习模型在泛化能力上会大幅退化,用这样的模型驱动的机器人在真实场景中会彻底“懵圈”,陷入什么也认不出的尴尬境地。
更有甚者,攻击者还可以精心调整“下毒”时所用的噪音数据,使得训练出来的机器人视觉模型“故意认错”某些东西,比如将障碍认成是通路,或将危险场景标记成安全场景等。
为了达成这一目的,这篇论文设计了一种可以生成对抗噪声的自编码器神经网络DeepConfuse。
通过观察一个假想分类器的训练过程更新自己的权重,产生“有毒性”的噪声,从而为“受害的”分类器带来最低下的泛化效率,而这个过程可以被归结为一个具有非线性等式约束的非凸优化问题。
下毒无痕,毒性不小
从实验数据可以发现,在MNIST、CIFAR-10以及缩减版的IMAGENET这些不同数据集上,使用“未被下毒”的训练数据集和“中毒”的训练数据集所训练的系统模型在分类精度上存在较大的差异,效果非常可观。
与此同时,从实验结果来看,该方法生成的对抗噪声具有通用性,即便是在随机森林和支持向量机这些非神经网络上也有较好表现。
其中,蓝色为使用“未被下毒”的训练数据训练出的模型在泛化能力上的测试表现,橙色为使用“中毒”训练数据训练出的模型的在泛化能力上的测试表现。
在CIFAR和IMAGENET数据集上的表现也具有相似效果,证明该方法所产生的对抗训练样本在不同的网络结构上具有很高的迁移能力。
此外,论文中提出的方法还能有效扩展至针对特定标签的情形下,即攻击者希望通过一些预先指定的规则使模型分类错误,例如将“猫”错误分类成“狗”,让模型按照攻击者计划,定向发生错误。
例如,下图为MINIST数据集上,不同场景下测试集上混淆矩阵的表现,分别为干净训练数据集、无特定标签的训练数据集、以及有特定标签的训练数据集。
实验结果有力证明,为有特定标签的训练数据集做相应设置的有效性,未来有机会通过修改设置以实现更多特定的任务。
对数据“下毒”技术的研究并不单单是为了揭示类似的AI入侵或攻击技术对系统安全的威胁,更重要的是,只有深入研究相关的入侵或攻击技术,才能有针对性地制定防范“AI黑客”的完善方案。
随着AI算法、AI系统在国计民生相关的领域逐渐得到普及与推广,科研人员必须透彻地掌握AI安全攻防的前沿技术,并有针对性地为自动驾驶、AI辅助医疗、AI辅助投资等涉及生命安全、财富安全的领域研发最有效的防护手段。
还关注联邦学习
除了安全问题之外,人工智能应用的数据隐私问题,也是创新工场AI安全实验室重点关注的议题之一。
近年来,随着人工智能技术的高速发展,社会各界对隐私保护及数据安全的需求加强,联邦学习技术应运而生,并开始越来越多地受到学术界和工业界的关注。
具体而言,联邦学习系统是一个分布式的具有多个参与者的机器学习框架,每一个联邦学习的参与者不需要与其余几方共享自己的训练数据,但仍然能利用其余几方参与者提供的信息更好的训练联合模型。
换言之,各方可以在在不共享数据的情况下,共享数据产生的知识,达到共赢。
创新工场AI工程院也十分看好联邦学习技术的巨大应用潜力。
今年3月,“Learning to Confuse: Generating Training Time Adversarial Data with Auto-Encoder”论文的作者、创新工场南京国际人工智能研究院执行院长冯霁代表创新工场当选为IEEE联邦学习标准制定委员会副主席,着手推进制定AI协同及大数据安全领域首个国际标准。
创新工场也将成为联邦学习这一技术“立法”的直接参与者。
创新工场AI工程院科研成绩单
创新工场凭借独特的VC+AI(风险投资与AI研发相结合)的架构,致力于扮演前沿科研与AI商业化之间的桥梁角色。
创新工场2019年广泛开展科研合作,与其他国际科研机构合作的论文,入选多项国际顶级会议,除上述介绍的“数据下毒”论文入选NeurlPS之外,还有8篇收录至五大学术顶会,涉及图像处理、自动驾驶、自然语言处理、金融AI和区块链等方向。
两篇论文入选ICCV
Disentangling Propagation and Generation for Video Prediction
https://arxiv.org/abs/1812.00452
这篇论文的主要工作围绕一个视频预测的任务展开,即在一个视频中,给定前几帧的图片预测接下来的一帧或多帧的图片。
Joint Monocular 3D Vehicle Detection and Tracking
https://arxiv.org/abs/1811.10742
这篇论文提出了一种全新的在线三维车辆检测与跟踪的联合框架,不仅能随着时间关联车辆的检测结果,同时可以利用单目摄像机获取的二维移动信息估计三维的车辆信息。
一篇论文入选IROS
Monocular Plan View Networks for Autonomous Driving
http://arxiv.org/abs/1905.06937
针对端到端的控制学习问题提出了一个对当前观察的视角转换,将其称之为规划视角,它把将当前的观察视角转化至一个鸟瞰视角。具体的,在自动驾驶的问题下,在第一人称视角中检测行人和车辆并将其投影至一个俯瞰视角。
三篇论文入选EMNLP
Multiplex Word Embeddings for Selectional Preference Acquisition
提出了一种multiplex词向量模型。在该模型中,对于每个词而言,其向量包含两部分,主向量和关系向量,其中主向量代表总体语义,关系向量用于表达这个词在不同关系上的特征,每个词的最终向量由这两种向量融合得到。
What You See is What You Get: Visual Pronoun Coreference Resolution in Dialogues
https://assert.pub/papers/1909.00421
提出了一个新模型(VisCoref)及一个配套数据集(VisPro),用以研究如何将代词指代与视觉信息进行整合。
Reading Like HER: Human Reading Inspired Extractive Summarization
人类通过阅读进行文本语义的摘要总结大体上可以分为两个阶段:1)通过粗略地阅读获取文本的概要信息,2)进而进行细致的阅读选取关键句子形成摘要。
本文提出一种新的抽取式摘要方法来模拟以上两个阶段,该方法将文档抽取式摘要形式化为一个带有上下文的多臂老虎机问题,并采用策略梯度方法来求解。
一篇论文入选IEEE TVCG
sPortfolio: Stratified Visual Analysis of Stock Portfolios
https://www.ncbi.nlm.nih.gov/pubmed/31443006
主要是对于金融市场中的投资组合和多因子模型进行可视分析的研究。通过三个方面的分析任务来帮助投资者进行日常分析并升决策准确性。
并提出了一个全新的可视化分析系统sPortfolio,它允许用户根据持仓,因子和历史策略来观察投资组合的市场。sPortfolio提供了四个良好协调的视图。
一篇论文入选NSDI
Monoxide: Scale Out Blockchain with Asynchronized Consensus Zones
https://www.usenix.org/system/files/nsdi19-wang-jiaping.pdf
提出了一种名为异步共识组 Monoxide 的区块链扩容方案,可以在由 4.8 万个全球节点组成的测试环境中,实现比比特币网络高出 1000 倍的每秒事务处理量,以及 2000 倍的状态内存容量,有望打破“不可能三角”这个长期困扰区块链性能的瓶颈。
独特的“科研助推商业”思路
国内VC,发表论文都很少见,为什么创新工场如此做?
这背后在于其“VC+AI”模式。
最独特之处在于,创新工场的AI工程院可以通过广泛的科研合作以及自身的科研团队,密切跟踪前沿科研领域里最有可能转变为未来商业价值的科研方向。
这种“科研助推商业”的思路力图尽早发现有未来商业价值的学术研究,然后在保护各方知识产权和商业利益的前提下积极与相关科研方开展合作。
同时,由AI工程院的产品研发团队尝试该项技术在不同商业场景里可能的产品方向、研发产品原型,并由商务拓展团队推动产品在真实商业领域的落地测试,继而可以为创新工场的风险投资团队带来早期识别、投资高价值赛道的宝贵机会。
“科研助推商业”并不是简单地寻找有前景的科研项目,而是将技术跟踪、人才跟踪、实验室合作、知识产权合作、技术转化、原型产品快速迭代、商务拓展、财务投资等多维度的工作整合在一个统一的资源体系内,用市场价值为导向,有计划地衔接学术科研与商业实践。
以AI为代表的高新技术目前正进入商业落地优先的深入发展期,产业大环境亟需前沿科研技术与实际商业场景的有机结合。
创新工场凭借在风险投资领域积累的丰富经验,以及在创办AI工程院的过程中积累的技术人才优势,特别适合扮演科研与商业化之间的桥梁角色。
于是,创新工场AI工程院也就顺势而生。
创新工场人工智能工程院成立于2016年9月,以“科研+工程实验室”模式,规划研发方向,组建研发团队。
目前已经设有医疗AI、机器人、机器学习理论、计算金融、计算机感知等面向前沿科技与应用方向的研发实验室,还先后设立了创新工场南京国际人工智能研究院、创新工场大湾区人工智能研究院。
目标是培养人工智能高端科研与工程人才,研发以机器学习为核心的前沿人工智能技术,并同各行业领域相结合,为行业场景提供一流的产品和解决方案。
而且, 创新工场还与国内外著名的科研机构广泛开展科研合作。
例如,今年3月20日,香港科技大学和创新工场宣布成立计算机感知与智能控制联合实验室(Computer Perception and Intelligent Control Lab)。
此外,创新工场也积极参与了国际相关的技术标准制定工作。例如,今年8月,第28届国际人工智能联合会议(IJCAI)在中国澳门隆重举办,期间召开了IEEE P3652.1(联邦学习基础架构与应用)标准工作组第三次会议。
IEEE联邦学习标准由微众银行发起,创新工场等数十家国际和国内科技公司参与,是国际上首个针对人工智能协同技术框架订立标准的项目。
创新工场表示,自身的科研团队将深度参与到联邦学习标准的制定过程中,希望为AI技术在真实场景下的安全性、可用性以及保护数据安全、保护用户隐私贡献自己的力量。
- 滴滴副总裁叶杰平离职,他是出行巨头的AI掌门人,战胜Uber中国的关键科学家2020-09-07
- 董明珠的格力空调卖不动了:上半年营收同比腰斩,24年来首次被美的反超2020-09-01
- 手机配件市场上的“隐形巨头”:80后长沙夫妻创办,IPO首日市值逼近600亿2020-08-31
- 寒武纪半年报:每天亏百万,销售力度提升营收反降11%,上市高峰市值跌去40%2020-08-30