铜灵 发自 凹非寺
量子位 出品 | 公众号 QbitAI
AI精准模仿你的声音,需要多大规模的训练?
浙江大学和微软的新研究证明,从0开始学习你的声音到准确逼真,AI只需要200个音频片段和相应标注,20分钟的素材就足够了。
并且,这是一种近乎无监督学习方法,只需少量标记和分类整理,直接投喂素材,就有千万个你的声音合成出来了。
如果投喂的是林志玲、郭德纲、新垣结衣的声音……
目前,这个AI系统的单词可识度准确率达到了99.84%,论文已经被机器学习顶会ICML 2019接收。
论文共同一作之一,还是位浙江大学的学霸本科生,目前大四在读。又一位别人家的本科生来了!
细看下这个研究。
四步合成法
这项研究中主要涉及两个任务,文本到语音(TTS,也就是语音合成)和自动语音识别(ASR),缺乏足够多的对齐数据(aligned data)是这两个领域的一大问题。
但在这项研究中,研究人员提出了一种新型的几乎无监督的TTS和ASR大法,通过利用一系列成对的语音和文本数据,和一部分额外的未配对数据,实现了小样本合成。
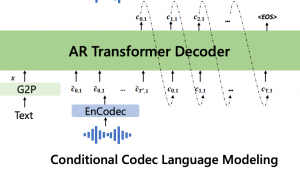
合成流程图如下图所示:
整个研究分为四个部分。
首先,研究人员通过自监督学习,利用语音和文本数据,建立了语音和文本领域的语言理解和建模能力。
具体来讲,他们使用去噪自编码器,在编码-解码框架中重建了语言和文本。
其次,研究人员通过对偶转换(Dual Transformation),分别训练模型将文本转为语音和将语音转为文本:
TTS模型将文本X转换为语音Y,ASR模型利用转换得到语音到文本数据进行训练;ASR模型将语音Y转换为文本X,然后TTS模型利用文本到语音数据训练。
对偶转换在TTS和ASR模型之间重复迭代,逐步提高两个任务的准确性。
因为语音序列通常比其它学习任务的序列更长,所以序列中的一个错误会导致更严重的影响。
因此,研究人员进一步利用文本和语音的双向序列建模(Bidirectional Sequence Modeling)减缓错错相传的问题。
最后,他们设计了一个基于Transformer的统一模型架构,能输入和输出语音和文本,并且能将上述模块整合在一起,实现TTS和ASR的功能。
远高于基线
研究人员将这个方法与其他系统在TTS和ASR任务上进行对比,并用MOS(平均主观意见分)衡量合成音与真实人声的相似度。
并且,用PER(音素错误率)衡量自动语音识别的表现。
结果显示,这种方法的TTS任务上的MOS分达到了2.68,在ASR任务上的PER达到了11.7%。
但从这两个成绩看,这种方法得分已经远高于200个配对样本的基线模型数据了。
此外,研究人员还分别将不同的添加到系统中,结果显示,当分别加入去噪自编码器(DAE)、对偶变换(DT)和双向序列建模(BSM)模块时,评分均有增高。
本科生一作
这篇论文出自一个全华人团队的,Yi Ren (任意)和Xu Tan是这篇论文的共同一作。
任意Linkedin主页显示,2015年在浙江大学计算机科学与技术专业入学后,任意先后在Dashbase、网易人工智能事业部、微软中国和一知智能实习过。
也就是说,在本科还没毕业的时候,当大家都在忙毕业论文之际,学霸已经是国际顶会的一作了。
谭旭是任意的师兄,2015年从浙大硕士毕业的,目前是微软亚洲研究院机器学习小组的副研究员。
Xu Tan主要研究方向在深度学习和分布式机器学习,以及它们在NLP、机器翻译、搜索和推荐排名中的应用。
此外,微软的Tao Qin、Sheng Zhao、Tie-Yan Liu和浙大的Zhou Zhao也是这篇论文的作者之一。
传送门
目前,项目地址和论文已经放出,研究人员表示代码也将在后面几周开源。
项目地址:
https://speechresearch.github.io/unsuper/
论文地址:
https://speechresearch.github.io/papers/almost_unsup_tts_asr_2019.pdf
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI · 头条号签约作者
վ’ᴗ’ ի 追踪AI技术和产品新动态