
PaddlePaddle升级解读 | PaddleHub轻松完成迁移学习
引言
迁移学习(Transfer Learning)是属于深度学习的一个子研究领域,该研究领域的目标在于利用数据、任务、或模型之间的相似性,将在旧领域学习过的知识,迁移应用于新领域中。迁移学习吸引了很多研究者投身其中,因为它能够很好的解决深度学习中的以下几个问题:
一些研究领域只有少量标注数据,且数据标注成本较高,不足以训练一个足够鲁棒的神经网络
大规模神经网络的训练依赖于大量的计算资源,这对于一般用户而言难以实现
应对于普适化需求的模型,在特定应用上表现不尽如人意
为了让开发者更便捷地应用迁移学习,百度PaddlePaddle开源了预训练模型管理工具PaddleHub。开发者用使用仅仅十余行的代码,就能完成迁移学习。本文将为读者全面介绍PaddleHub并介绍其应用方法。
项目地址:
https://github.com/PaddlePaddle/PaddleHub
PaddleHub介绍
PaddleHub是基于PaddlePaddle开发的预训练模型管理工具,可以借助预训练模型更便捷地开展迁移学习工作,旨在让PaddlePaddle生态下的开发者更便捷体验到大规模预训练模型的价值。
PaddleHub目前的预训练模型覆盖了图像分类、目标检测、词法分析、Transformer、情感分析五大类别。 未来会持续开放更多类型的深度学习模型,如语言模型、视频分类、图像生成等预训练模型。PaddleHub的功能全景如图1所示。
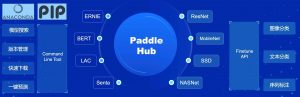
图1 PaddleHub功能全景
PaddleHub主要包括两个功能:命令行工具和Fine-tune API。
命令行工具
PaddleHub借鉴了Anaconda和PIP等软件包管理的理念,开发了命令行工具,可以方便快捷的完成模型的搜索、下载、安装、预测等功能,对应的关键的命令分别是search,download,install,run等。我们以run命令为例,介绍如何通过命令行工具进行预测。
Run命令用于执行Module的预测,这里分别举一个NLP和CV的例子。
对于NLP任务:输入数据通过—input_text指定。以百度LAC模型(中文词法分析)为例,可以通过以下命令实现单行文本分析。
# 单文本预测
$ hub run lac –input_text “今天是个好日子”
对于CV任务:
输入数据通过—input_path指定。以SSD模型(单阶段目标检测)为例子,可以通过以下命令实现单张图片的预测
# 使用SSD检测模型对图片进行目标检测,第一条命令是下载图片,第二条命令是执行预测,用户也可以自
# 己准备图片
$ wget –no-check-certificate https://paddlehub.bj.bcebos.com/resources/test_img_bird.jpg
$ hub run ssd_mobilenet_v1_pascal –input_path test_img_bird.jpg
更多的命令用法,请读者参考文首的Github项目链接。
Fine-tune API:
PaddleHub提供了基于PaddlePaddle实现的Fine-tune API, 重点针对大规模预训练模型的Fine-tune任务做了高阶的抽象,让预训练模型能更好服务于用户特定场景的应用。通过大规模预训练模型结合Fine-tune,可以在更短的时间完成模型的收敛,同时具备更好的泛化能力。PaddleHub API的全景如图2所示。
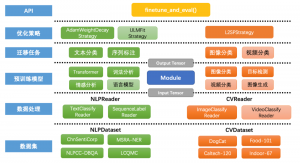
图2 PaddleHub Fine-tune API全景
Fine-tune :对一个Task进行Fine-tune,并且定期进行验证集评估。在Fine-tune的过程中,接口会定期的保存checkpoint(模型和运行数据),当运行被中断时,通过RunConfig指定上一次运行的checkpoint目录,可以直接从上一次运行的最后一次评估中恢复状态继续运行。
迁移任务Task:在PaddleHub中,Task代表了一个Fine-tune的任务。任务中包含了执行该任务相关的program以及和任务相关的一些度量指标(如分类准确率accuracy、precision、 recall、 F1-score等)、模型损失等。
运行配置 RunConfig:在PaddleHub中,RunConfig代表了在对Task进行Fine-tune时的运行配置。包括运行的epoch次数、batch的大小、是否使用GPU训练等。
优化策略Strategy:在PaddleHub中,Strategy类封装了一系列适用于迁移学习的Fine-tune策略。Strategy包含了对预训练参数使用什么学习率变化策略,使用哪种类型的优化器,使用什么类型的正则化等。
预训练模型Module :Module代表了一个可执行的模型。这里的可执行指的是,Module可以直接通过命令行hub run ${MODULE_NAME}执行预测,或者通过context接口获取上下文后进行Fine-tune。在生成一个Module时,支持通过名称、url或者路径创建Module。
数据预处理Reader :PaddleHub的数据预处理模块Reader对常见的NLP和CV任务进行了抽象。
数据集Dataset:PaddleHub提供多种NLP任务和CV任务的数据集,可供用户载,用户也可以在自定义数据集上完成Fine-tune。
基于以上介绍的PaddleHub两大功能,用户可以实现:
无需编写代码,一键使用预训练模型进行预测;
通过hub download命令,快速地获取PaddlePaddle生态下的所有预训练模型;
借助PaddleHub Fine-tune API,使用少量代码完成迁移学习。
以下将从实战角度,教你如何使用PaddleHub进行图像分类迁移。
PaddleHub实战
1. 安装
PaddleHub是基于PaddlePaddle的预训练模型管理框架,使用PaddleHub前需要先安装PaddlePaddle,如果你本地已经安装了CPU或者GPU版本的PaddlePaddle,那么可以跳过以下安装步骤。
$ pip install paddlepaddle #CPU安装命令
或者
$ pip install paddlepaddle-gpu # GPU安装
推荐使用大于1.4.0版本的PaddlePaddle。
通过以下命令来安装PaddleHub
$ pip install paddlehub
2. 选择合适的模型
首先导入必要的python包
# -*- coding: utf8 -*-
import paddlehub as hubimport paddle.fluid as fluid
接下来我们要在PaddleHub中选择合适的预训练模型来Fine-tune,由于猫狗分类是一个图像分类任务,因此我们使用经典的ResNet-50作为预训练模型。PaddleHub提供了丰富的图像分类预训练模型,包括了最新的神经网络架构搜索类的PNASNet,我们推荐你尝试不同的预训练模型来获得更好的性能。
module_map = {
“resnet50”: “resnet_v2_50_imagenet”,
“resnet101”: “resnet_v2_101_imagenet”,
“resnet152”: “resnet_v2_152_imagenet”,
“mobilenet”: “mobilenet_v2_imagenet”,
“nasnet”: “nasnet_imagenet”,
“pnasnet”: “pnasnet_imagenet”
}
module_name = module_map[“resnet50”]
module = hub.Module(name = module_name)
3. 数据准备
接着需要加载图片数据集。为了快速体验,我们直接加载PaddleHub提供的猫狗分类数据集,如果想要使用自定义的数据进行体验,请查看自定义数据。
# 直接用PaddleHub提供的数据集
dataset = hub.dataset.DogCat()
4.自定义数据
本节说明如何组装自定义的数据,如果想使用猫狗数据集进行体验,可以直接跳过本节。
使用自定义数据时,我们需要自己切分数据集,将数据集且分为训练集、验证集和测试集。
同时使用三个文本文件来记录对应的图片路径和标签,此外还需要一个标签文件用于记录标签的名称。
├─data: 数据目录
├─train_list.txt:训练集数据列表
├─test_list.txt:测试集数据列表
├─validate_list.txt:验证集数据列表
├─label_list.txt:标签列表
└─……
训练/验证/测试集的数据列表文件的格式如下
图片1路径 图片1标签
图片2路径 图片2标签
…
标签列表文件的格式如下
分类1名称
分类2名称
…
使用如下的方式进行加载数据,生成数据集对象
注意事项:
- num_labels要填写实际的分类数量,如猫狗分类该字段值为2,food101该字段值为101,下文以2为例子
- base_path为数据集实际路径,需要填写全路径,下文以/test/data为例子
- 训练/验证/测试集的数据列表文件中的图片路径需要相对于base_path的相对路径,例如图片的实际位置为/test/data/dog/dog1.jpg,base_path为/test/data,则文件中填写的路径应该为dog/dog1.jpg
# 使用本地数据集
dataset = MyDataSet()
class MyDataSet(hub.dataset.basecvdataset.ImageClassificationDataset):
def __init(self):
self.base_path = “/test/data”
self.train_list_file = “train_list.txt”
self.test_list_file = “test_list.txt”
self.validate_list_file = “validate_list.txt”
self.label_list_file = “label_list.txt”
self.label_list = None
self.num_labels = 2
5.生成Reader
接着生成一个图像分类的reader,reader负责将dataset的数据进行预处理,接着以特定格式组织并输入给模型进行训练。
当我们生成一个图像分类的reader时,需要指定输入图片的大小
data_reader = hub.reader.ImageClassificationReader(
image_width=module.get_expected_image_width(),
image_height=module.get_expected_image_height(),
images_mean=module.get_pretrained_images_mean(),
images_std=module.get_pretrained_images_std(),
dataset=dataset)
6.组建Fine-tune Task
有了合适的预训练模型和准备要迁移的数据集后,我们开始组建一个Task。
由于猫狗分类是一个二分类的任务,而我们下载的cv_classifer_module是在ImageNet数据集上训练的千分类模型,所以我们需要对模型进行简单的微调,把模型改造为一个二分类模型:
- 获取cv_classifer_module的上下文环境,包括输入和输出的变量,以及Paddle Program;
- 从输出变量中找到特征图提取层feature_map;
- 在feature_map后面接入一个全连接层,生成Task;
input_dict, output_dict, program = module.context(trainable=True)
img = input_dict[“image”]
feature_map = output_dict[“feature_map”]
task = hub.create_img_cls_task(
feature=feature_map, num_classes=dataset.num_labels)
feed_list = [img.name, task.variable(“label”).name]
7.选择运行时配置
在进行Fine-tune前,我们可以设置一些运行时的配置,例如如下代码中的配置,表示:
use_cuda:设置为False表示使用CPU进行训练。如果本机支持GPU,且安装的是GPU版本的PaddlePaddle,我们建议你将这个选项设置为True;
epoch:要求Fine-tune的任务只遍历1次训练集;
batch_size:每次训练的时候,给模型输入的每批数据大小为32,模型训练时能够并行处理批数据,因此batch_size越大,训练的效率越高,但是同时带来了内存的负荷,过大的batch_size可能导致内存不足而无法训练,因此选择一个合适的batch_size是很重要的一步;
log_interval:每隔10 step打印一次训练日志;
eval_interval:每隔50 step在验证集上进行一次性能评估;
checkpoint_dir:将训练的参数和数据保存到cv_Fine-tune_turtorial_demo目录中;
strategy:使用DefaultFine-tuneStrategy策略进行Fine-tune;
更多运行配置,请查看文首的Github项目链接。
config = hub.RunConfig(
use_cuda=False,
num_epoch=1,
checkpoint_dir=”cv_finetune_turtorial_demo”,
batch_size=32,
log_interval=10,
eval_interval=50,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
8.开始Fine-tune
我们选择Fine-tune_and_eval接口来进行模型训练,这个接口在Fine-tune的过程中,会周期性的进行模型效果的评估,以便我们了解整个训练过程的性能变化。
hub.finetune_and_eval(
task, feed_list=feed_list, data_reader=data_reader, config=config)
9.查看训练过程的效果
训练过程中的性能数据会被记录到本地,我们可以通过visualdl来可视化这些数据。
我们在shell中输入以下命令来启动visualdl,其中${HOST_IP}为本机IP,需要用户自行指定
$ visualdl —logdir ./ cv_finetune_turtorial_demo/vdllog —host ${HOST_IP} —port 8989
启动服务后,我们使用浏览器访问${HOST_IP}:8989,可以看到训练以及预测的loss曲线和accuracy曲线,如下图所示。
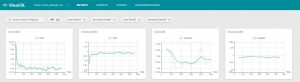
10.使用模型进行预测
当Fine-tune完成后,我们使用模型来进行预测,整个预测流程大致可以分为以下几步:
- 构建网络
- 生成预测数据的Reader
- 切换到预测的Program
- 加载预训练好的参数
- 运行Program进行预测
通过以下命令来获取测试的图片(适用于猫狗分类的数据集)
$ wget —no-check-certificate https://PaddleHub.bj.bcebos.com/resources/test_img_cat.jpg
$ wget —no-check-certificate https://PaddleHub.bj.bcebos.com/resources/test_img_dog.jpg
注意:其他数据集所用的测试图片请自行准备
完整预测代码如下:
import os
import numpy as np
import paddle.fluid as fluid
import paddlehub as hub
# Step 1: build Program
module_map = {
“resnet50”: “resnet_v2_50_imagenet”,
“resnet101”: “resnet_v2_101_imagenet”,
“resnet152”: “resnet_v2_152_imagenet”,
“mobilenet”: “mobilenet_v2_imagenet”,
“nasnet”: “nasnet_imagenet”,
“pnasnet”: “pnasnet_imagenet”
}
module_name = module_map[“resnet50”]
module = hub.Module(name = module_name)
input_dict, output_dict, program = module.context(trainable=False)
img = input_dict[“image”]
feature_map = output_dict[“feature_map”]
dataset = hub.dataset.DogCat()
task = hub.create_img_cls_task(
feature=feature_map, num_classes=dataset.num_labels)
feed_list = [img.name]
# Step 2: create data reader
data = [
“test_img_dog.jpg”,
“test_img_cat.jpg”
]
data_reader = hub.reader.ImageClassificationReader(
image_width=module.get_expected_image_width(),
image_height=module.get_expected_image_height(),
images_mean=module.get_pretrained_images_mean(),
images_std=module.get_pretrained_images_std(),
dataset=None)
predict_reader = data_reader.data_generator(
phase=”predict”, batch_size=1, data=data)
label_dict = dataset.label_dict()
# Step 3: switch to inference program
with fluid.program_guard(task.inference_program()):
# Step 4: load pretrained parameters
place = fluid.CPUPlace()
exe = fluid.Executor(place)
pretrained_model_dir = os.path.join("cv_finetune_turtorial_demo", "best_model")
fluid.io.load_persistables(exe, pretrained_model_dir)
feeder = fluid.DataFeeder(feed_list=feed_list, place=place)
# Step 5: predict
for index, batch in enumerate(predict_reader()):
result, = exe.run(
feed=feeder.feed(batch), fetch_list=[task.variable('probs')])
predict_result = np.argsort(result[0])[::-1][0]
print("input %i is %s, and the predict result is %s" %
(index+1, data[index], label_dict[predict_result]))- 长城汽车自研芯片点亮!提前布局下一代架构RISC-V,魏建军:不能再受制于人2024-09-27
- 腾讯云发布自研大数据高性能计算引擎Meson,性能最高提升6倍2024-07-04
- Intel2024-03-18
- 数字员工全新发布 加速企业转型2024-01-15










{kind=link}
{kind=link}