中国学霸本科生提出AI新算法:速度比肩Adam,性能媲美SGD
晓查 乾明 发自 凹非寺
量子位 报道 | 公众号 QbitAI
两位学霸本科生,一位来自北大,一位来自浙大。
他们在实习期间,研究出一种新的AI算法,相关论文已经被人工智能顶级会议ICLR 2019收录,并被领域主席赞不绝口,给出5分评价。
在这篇论文中,他们公布了一个名为AdaBound的神经网络优化算法,简单地说,这个算法训练速度比肩Adam,性能媲美SGD。
这个算法适用于CV、NLP领域,可以用来开发解决各种流行任务的深度学习模型。而且AdaBound对超参数不是很敏感,省去了大量调参的时间。
两位本科生作为共同一作的这篇论文,也在Reddit上引发了热赞,作者本人也在这个论坛上展开了在线的答疑交流。
AdaBound已经开源,还放出了Demo。
AdaBound是什么
AdaBound结合了SGD和Adam两种算法,在训练开始阶段,它能像Adam一样快速,在后期又能像SGD一样有很好的收敛性。
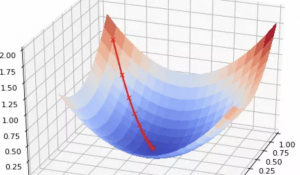
SGD(随机梯度下降)算法历史悠久,它是让参数像小球滚下山坡一样,落入山谷,从而获得最小值。
但它最大的缺点是下降速度慢(步长是恒定值),而且可能会在沟壑的两边持续震荡,停留在一个局部最优点。
Adam(自适应矩估计)就是为了提高训练速度而生的。它和自适应优化方法AdaGrad、RMSProp等一样,通过让小球在更陡峭的山坡上下降,速率加快,来更快地让结果收敛。
虽然Adam算法跑得比SGD更快,却存在两大缺陷:结果可能不收敛、可能找不到全局最优解。也就是说它的泛化能力较差,在解决某些问题上,表现还不如SGD。
而造成这两大缺陷的原因,可能是由于不稳定和极端的学习率。
AdaBound是如何解决这个问题的?
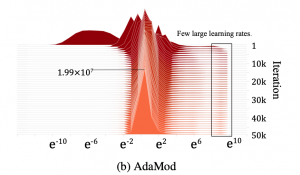
它给学习率划出动态变化的界限,让实现从Adam到SGD的渐进和平滑过渡,让模型在开始阶段有和Adam一样快的训练速度,后期又能保证和SGD一样稳定的学习率。
这种思路是受到2017年Salesforce的研究人员的启发。他们通过实验发现,Adam后期的学习率太低影响了收敛结果。如果控制一下Adam的学习率的下限,实验结果会好很多。
对学习率的控制就和梯度裁剪差不多。在防止梯度爆炸问题上,我们可以剪掉大于某个阈值的梯度。同样的,我们也可以剪裁Adam学习率实现AdaBound。
在上面的公式中,学习率被限制在下限 η 和上限 η之间。当η = η = α时,就是SGD算法;当η=0、 η =∞时,就是Adam算法。
为了实现从Adam到SGD的平滑过渡,让η 和 η变成随时间变化的函数:η 递增从0收敛到α,η从∞递减收敛到α。
在这种情况下,AdaBound开始时就像Adam一样训练速度很快,随着学习率边界越来越受到限制,它又逐渐转变为SGD。
AdaBound还有个非常大的优点,就是它对超参数不是很敏感,省去了大量调参的时间。
实验结果
作者分别对不同模型进行实验,比较了Adam与业界流行方法SGD,AdaGrad,Adam和AMSGrad在训练集和测试集上的学习曲线。
以上结果证明了AdaBound确实有比SGD更快的训练速度。
在LSTM上的实验则证明Adam更好的泛化能力。Adam算法在该实验条件下没有收敛到最优解,而AdaBound和SGD算法一样收敛到最优解。
上图中,还无法完全体现AdaBound算法相比SGD的在训练速度上的优点,但AdaBound对超参数不敏感,是它相比SGD的另一大优势。
但使用AdaBound不代表完全不需要调参,比如上图中α=1时,AdaBound的表现很差,简单的调整还是需要的。
目前实验结果的测试范围还比较小,评审认为论文可以通过更大的数据集,比如CIFAR-100,来获得更加可信的结果。
Reddit网友也很好奇AdaBound在GAN上的表现,但作者表示自己计算资源有限,还没有在更多的模型上测试。希望在开源后有更多人验证它的效果。
自己动手
目前作者已经在GitHub上发布了基于PyTorch的AdaBound代码。
它要求安装Python 3.6或更高版本,可以用pip直接安装:
pip install adabound
使用方法和Pytorch其他优化器一样:
optimizer = adabound.AdaBound(model.parameters(), lr=1e-3, final_lr=0.1)
作者还承诺不久后会推出TensorFlow版本,让我们拭目以待。
学霸本科生
这项研究的共同一作,是两位学霸本科生。他们在滴滴实习的时候一起完成了这项研究。
一位名叫骆梁宸,就读于北京大学地球与空间科学学院,今年大四。
另一位名叫熊远昊,就读于浙江大学信电学院,今年也是大四。
骆梁宸
这名学霸今年大四,已经有四篇一作论文被人工智能顶级学术会议收录,其中1篇EMNLP 2018、2篇AAAI 2019,还有我们今天介绍的这篇,发表于ICLR 2019。
他高中毕业于北京师范大学附属实验中学,连续三年获得全国青少年信息学奥林匹克竞赛一等奖。
在2015年到2018年期间,是北大PKU Helper团队的安卓开发工程师和负责人。
2016年春季,担任数据结构与算法课程助教,还带着实验室同学们开发了一个回合制的游戏平台坦克大战。
2016年7月到2017年6月,担任UniBike技术开发VP,负责软件开发。
2017年7月到2018年5月,在微软亚洲研究院实习,做研究助理。在这段研究经历中,发表了两篇被AAAI收录的论文。
2018年7月至今,在滴滴人工智能实验室做研究助理,本篇文章介绍的研究成果,就是这一工作中的成果。
目前,他也在北大语言计算与机器学习组实习,导师为研究员孙栩,也是这篇论文的作者之一。
熊远昊
他现在是浙江大学信电学院信息工程专业的大四学生,同样是学霸级人物,三年综合成绩排名年级第一。
在发表这篇ICLR论文之前,他还以第二作者身份在通信领域的权威期刊上发表过论文1篇。
此外,论文还有一位作者,是南加州大学的副教授Yan Liu。
如果,你对他们的研究感兴趣,请收好下面的传送门:
论文:
ADAPTIVE GRADIENT METHODS WITH DYNAMIC BOUND OF LEARNING RATE
https://openreview.net/pdf?id=Bkg3g2R9FX
论文评审页面:
https://openreview.net/forum?id=Bkg3g2R9FX
GitHub地址:
https://github.com/Luolc/AdaBound
Reddit讨论地址:
https://www.reddit.com/r/MachineLearning/comments/auvj3q/r_adabound_an_optimizer_that_trains_as_fast_as/
- 脑机接口走向现实,11张PPT看懂中国脑机接口产业现状|量子位智库2021-08-10
- 张朝阳开课手推E=mc²,李永乐现场狂做笔记2022-03-11
- 阿里数学竞赛可以报名了!奖金增加到400万元,题目面向大众公开征集2022-03-14
- 英伟达遭黑客最后通牒:今天必须开源GPU驱动,否则公布1TB机密数据2022-03-05